
核心功能
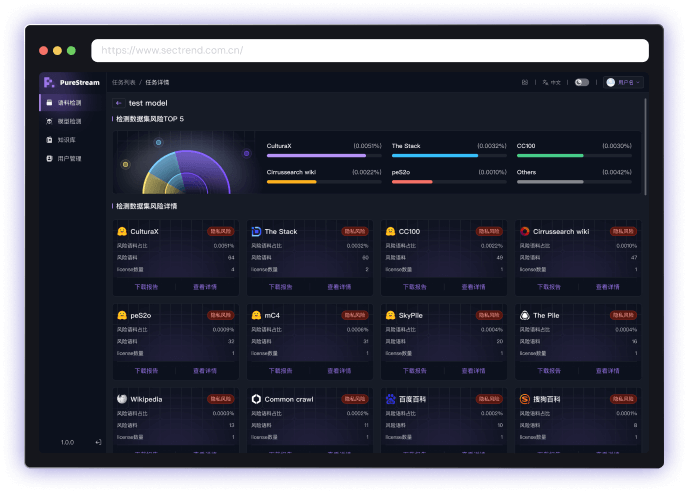
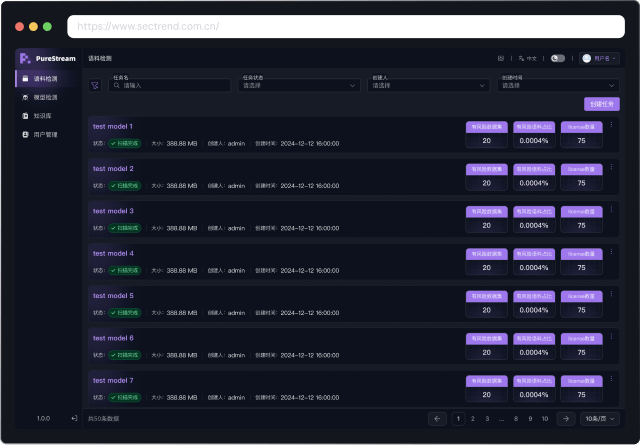
深度的语料库检测与风险识别
支持清晰追溯数据集来源及构成,防范法律风险;展示数据集名称、风险占比等详细风险指标,并提供包含关键本地模型与匹配模型信息的精准模型溯源功能
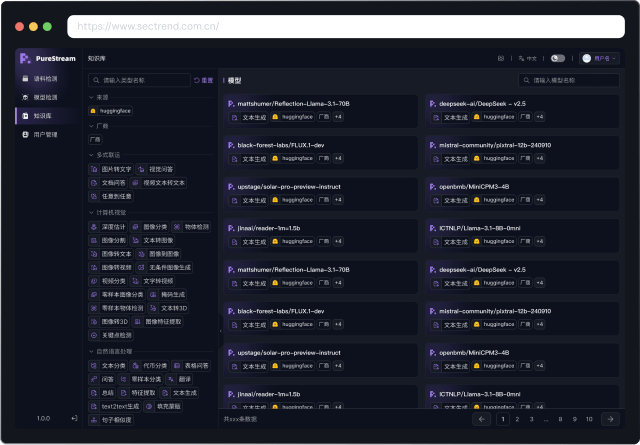
模型知识库
支持按模型来源及类型检索,为开发人员、研究人员及部署团队提供模型详细特征、性能数据与使用指南;展示模型名称、类型、架构、训练数据集等关键数据
可视化数据总览
提供直观的仪表盘与图表,将软件成分、策略告警及安全风险等以可视化形式呈现;实时监控AI模型状态,助力管理者从多维度研发视角快速评估风险与合规状况
AI生成代码漏洞检测
识别数据污染、模型欺骗等AI特定风险;对漏洞从发现到解决进行全流程追踪,形成完整修复闭环,帮助团队尽早规避威胁、降低修复成本
AI 知识产权合规分析
聚焦开源及AI模型许可证合规性,精准识别并解析各类许可证;支持自定义审计策略与多格式报告生成,助力管理软件供应链安全与合规风险
产品创新点
基于大数据及AI/ML算法的
海量数据
3亿+
组件
1000亿+
文件
30万亿+
代码
200+
代码仓库
24h
不间断爬取
10-20TB
知识库
基于算法叠加 实现海量数据高效精准检索匹配

自有数据结构

数十种算法

万亿代码匹配
基于大数据和AI算法 实现软件开发全生命周期安全与合规管控

大数据算法

实时监控

合规检测
技术
大模型算法识别ModelCard
借助预训练大模型的无监督学习能力对ModelCard数据少量有监督微调,或利用其命名实体识别能力,识别ModelCard里关键实体及关系,整合提取的信息,构建完整ModelCard信息结构
降维压缩技术
为确保用户数据安全,在上传模型检测前,用户可利用清流 PureStream 自研降维压缩引擎,在本地对检测目标作降维压缩散列处理,生成不可逆加密代码指纹信息后上传。存储模型主机无需连接平台,全程不接触用户源代码
复杂多场景模型探测技术
针对模型融合、重新切分、量化及裁剪等多种操作场景,通过分析融合后层的特征提取,确定原始特征维度与表示方式。利用特征空间相似性,采用计算特征距离或特征映射等方法,使探测技术适配融合或切分后的模型
基于词向量/大语言模型技术
运用基于词向量、语言模型及大语言模型(如 BERT、GPT)的高级文本分析技术,可进行精细化代码对比、文本溯源与安全分析以及许可证文本匹配与合规分析
文本解析及自然语言处理技术
需要解析代码注释、文档和许可证文本等自然语言内容,NLP技术可以帮助工具理解这些文本,提取关键信息,如许可证要求、组件描述等
图神经网络技术
在处理软件依赖关系图时,图神经网络可以学习图的结构和节点之间的关系,从而帮助工具识别潜在的依赖关系问题或漏洞